
Go 基础
Go 语言是谷歌 2009 年首次推出并在 2012 年正式发布的一种全新的编程语言,可以在不损失应用程序性能的情况下降低代码的复杂性。
下面是 Go 的 “Hello world”程序:
package main
import "fmt"
func main(){
fmt.Println("Hello Go!")
}
题外话:
Foo 是一个编程中经常使用的占位符,它没有特定的含义。“foo” 这个词的确有很多不同的起源说法。以下是一些可能的来源:
“Foo” 来自于 “FUBAR”,这个说法已经在前面提到过了。FUBAR 是 “Fucked Up Beyond All Recognition” 的缩写,意为 “完全搞砸了”。“Foo” 可能是在这个词的基础上发展而来的。
“Foo” 作为占位符的使用可以追溯到 1965 年,当时计算机科学家 Melvin Conway 在一篇论文中使用了 “foo” 和 “bar” 作为变量名。他认为这些词听起来有趣,可以使代码更易于阅读。
“Foo” 来自于纽约的一个餐厅,当时计算机科学家们在那里举行了一个会议。他们使用 “foo” 来代表那个餐厅的名字,后来这个词就成为了占位符的代名词。
Go
在 Linux 操作系统中,我们安装 Go 之后可以使用命令管理工具来对 Go 进行管理。
[root@yikuanzz ~]# go -help
Go is a tool for managing Go source code.
Usage:
go <command> [arguments]
The commands are:
bug start a bug report
build compile packages and dependencies
clean remove object files and cached files
doc show documentation for package or symbol
env print Go environment information
fix update packages to use new APIs
fmt gofmt (reformat) package sources
generate generate Go files by processing source
get add dependencies to current module and install them
install compile and install packages and dependencies
list list packages or modules
mod module maintenance
work workspace maintenance
run compile and run Go program
test test packages
tool run specified go tool
version print Go version
vet report likely mistakes in packages
Use "go help <command>" for more information about a command.
Additional help topics:
buildconstraint build constraints
buildmode build modes
c calling between Go and C
cache build and test caching
environment environment variables
filetype file types
go.mod the go.mod file
gopath GOPATH environment variable
gopath-get legacy GOPATH go get
goproxy module proxy protocol
importpath import path syntax
modules modules, module versions, and more
module-get module-aware go get
module-auth module authentication using go.sum
packages package lists and patterns
private configuration for downloading non-public code
testflag testing flags
testfunc testing functions
vcs controlling version control with GOVCS
Use "go help <topic>" for more information about that topic.
通过 build 命令,我们可以对 Go 程序进行编译;clean 命令则会删除编译生成的可执行文件;run 命令则是编译并且运行。
除了上面这些常用的命令外,还有一些好用的命令也是值得介绍的:
go vet可以辅助捕获常见的错误;go fmt会将你的代码布局成和 Go 源码类似的风格;go doc能阅读包的文档内容,也可以自己去写代码的文档。
包
所有 Go 语言程序会被组成很多组的文件。每一个组就叫做包,放在同个文件夹内。这样每个包的代码都可以作为很小的复用单元,被其他项目引用。
比如,我们在程序开头声明的就是该程序文件所属的包 package main。
创建一个 Go 工程主要步骤如下:
-
1.新建工程文件目录
goproject。mkdir goproject -
2.在工程文件中新建
src、pkg、bin文件目录。cd goproject mkdir src pkg bin -
3.在 GOPYAH 中添加工程路径。
go env GOATH="/home/goproject" -
4.在
src文件目录下新建自己的包example文件目录。cd ./src mkdir example -
5.在
src下编写主程序代码goproject.go。 -
6.在
example文件内编写example.go和包测试文件example_test.go。 -
7.编译调试包。
go build example go test example go install example -
8.编译主程序。
go build goproject.go -
9.运行主程序。
./goproject
其中,GOPATH 为工程根目录,bin 用来存放生成的可执行文件,pkg 用来生成 .a 文件,在 golang 中的 import name 实际上是去 GoPATH 中寻找 name.a 文件。
在 Go 语言中,会将命名为 main 的包编译成为 二进制可执行程序。
如果某个包名叫 main ,那么其中一定会有名为 main() 的函数。
比如,我们在 $GOPAHT/src/hello 目录中创建 hello.go 并写入我们的“Hello world”程序,然后通过 go build 命令对该程序进行编译,它会产生一个 hello 的可执行程序。
[root@yikuanzz hello]# ./hello
Hello world!
导包
我们注意到程序中,有使用 import "fmt" 的语句。编译器会使用 Go 环境变量设置的路径,通过引入相对路径来去查找磁盘上的包。插个题外话,如果导入包却不适用包中的代码,则会报错。
但是,我们的 $GOPATH 路径上并没有名为 fmt 的包,显然这是标准库中的包,那么这个查找顺序是怎么样的呢?
举例,如果 Go 安装在 /usr/local/go 路径下,且 GOPATH=/home/myproject:/home/mylibraries的话,那么我们去查找 net/http 包就会按照以下顺序去做:
-
1、
/usr/local/go/src/pkg/net/http; -
2、
/home/myproject/src/net/http; -
3、
/home/mylibraries/src/net/http。
如果所有目录上都没找到要导入的包,那么我们对程序进行 run 或 build 的时候就会出错。后面,我们会介绍 go get 命令来进行处理。
除了本地导入以外,我们也可以通过远程来导入包,比如 import "github.com/spf13/viper"。
当我们的包路径包含 URL 时,Go 工具链就会使用 分布式版本控制系统(Distributed Version Control Systems,DVCS)来获取包,并且将包的源代码保存在 GOPATH 执行的路径里与 URL 匹配的目录里。
这个过程通过 go get 命令完成,go get 将获取任意指定的 URL 的包。
当我们用的包多起来的时候,就可能会有相同的包名,这时我们可以对包导入进行重命名,就像下面的代码这样:
package main
import (
"fmt"
myfmt "mylib/fmt"
)
func main(){
fmt.Println("Standard Library")
myfmt.Println("mylib/fmt")
}
函数 init
每个包可以包含任意多个 init 函数,这些函数都会在程序执行开始的时候被调用。所有被编译器发现的 init 函数都会安排在 main 函数之前执行。
比如,我们看一下 PostgreSQL 数据库驱动中的一段代码:
package postgres
import "database/sql"
func init(){
sql.Register("postgres", new(PostgresDriver))
}
如果程序导入了这个包,就会调用 init 函数,促使 PostgreSQL 的驱动最终注册到 Go 的 sql 包里,成为一个可用的驱动。
为了要注册这个驱动,我们就要导入这个包,但是呢,我们又不使用包内的代码,只是想要这 init 函数执行。
那么,在导包的时候需要给包重新命名,要用到 _ 符号。这样一来,我们可以将驱动注册到 sql 包里面了:
package main
import (
"database/sql"
_ "dbdriver/postgres"
)
func main(){
sql.Open("postgres", "mydb")
}
依赖管理
上面的内容,我们介绍了 Go 的依赖管理方法,就是通过 GOPATH 的方式来管理包和依赖,这样的方式存在很多弊端,也不利于项目的构建。
因此,社区中出现了很多工具可供我们选择,比如 godep、vender、gb 等等。
这里我们介绍一下 gb 工程的样式:
/home/bill/devel/myproject ($PROJECT)
|-- src
| |-- cmd
| | |-- myproject
| | | |-- main.go
| |-- examples
| |-- model
| |-- README.md
|-- vendor
|-- src
|-- bitbucket.org
| |-- ww
| |-- goautoneg
| |-- Makefile
| |-- README.txt
| |-- autoneg.go
| |-- autoneg_test.go
|-- github.com
|-- beorn7
|-- perks
|-- README.md
|-- quantile
|-- bench_test.go
|-- example_test.go
|-- exampledata.txt
|-- stream.go
gb 工程会区分开发人员的代码和开发人员需要依赖的代码。开发人员的代码放在 $PROJECT/src/ 中,第三方代码放在 $PROJECT/vendor/src中。
接下来,我们做一个实例,尝试创建一个 gb 工程:
1、首先我们先安装 gb 工具:(要将 $GOPATH/bin 加入到环境变量中 export PATH=$PATH:$GOPATH/bin )
[root@yikuanzz ~]# go get github.com/constabulary/gb/...
2、我们创建一个文件夹 demo-project 和目录下的 src/hello 文件夹:
[root@yikuanzz ~]# mkdir /home/demo-project
[root@yikuanzz ~]# mkdir -p /home/demo-project/src/hello
[root@yikuanzz ~]# tree /home/demo-project/
/home/demo-project/
└── src
└── hello
2 directories, 0 files
3、然后我们将写一个简单的 ”Hello world“ 程序到 hello.go 文件中:
[root@yikuanzz ~]# tree /home/demo-project/
/home/demo-project/
└── src
└── hello
└── hello.go
2 directories, 1 file
4、进入到目录下,对项目进行编译和运行:
[root@yikuanzz demo-project]# gb build all
hello
[root@yikuanzz demo-project]# bin/hello
Hello gb
[root@yikuanzz demo-project]# tree
/home/demo-project/
├── bin
│ └── hello
└── src
└── hello
└── hello.go
Go 数据结构
数组
数组的最大一个特点就是占用的内存是连续分布的。
- CPU 能将正在使用的数据缓存更久;
- 容易计算索引,迭代元素。
// 声明一个包含 5 个 int 元素的数组
var array [5]int
数组初始化时,每个元素都为对应类型的零值。
如果想要更加快速地创建数组,可以使用数组字面量。
// 声明一个包含 5 个 int 元素的数组 并且 初始化每个元素
array := [5]int {10, 20, 30, 40 ,50}
当然,我们可以让 Go 根据元素的数量来确定数组长度。
// 容量初始化值的数量决定
array := [...]int {10, 20, 30, 40, 50}
此外,我们也可以指定对应元素的初始化值。
// 指定 索引2 和 索引3 的值
array := [5]int {2: 30, 3:40}
除了通过 [] 运算符来访问数组,我们还可以通过指针访问值。
// 数组元素为 整型指针
arrary := [5]*int {0: new(int), 1:new(int)}
// 给 索引0 和 索引1 赋值
*array[0] = 10
*array[1] = 20
在 Go 语言中,数组是一个值。所以,数组是可以用在赋值上的,这样就可以复制数组。
// 声明一个包含 5 个字符串的数组
var array1 [5]string
// 声明另一个包含 5 个字符串的数组 并且 初始化
array2 = [5]string {"Red", "Blue", "Green", "Yellow", "Pink"}
// 把 array2 值复制给 array1
array1 = array2
此外,如果复制的是指针数组的话,则是将指针地址的值复制了一遍,它们都指向同一个内容。
多维度数组也是数组中的一个重要内容,它可以很容易地管理具父子关系的数据或者与坐标相关联的数据。
// 声明一个二维整型数组,维度为 4 和 2
var array [4][2]int
// 数组字面量声明
array := [4][2]int {{10, 11}, {20, 21}, {30, 31}, {40, 41}}
在函数间传递数组是一个很大的开销,因为函数变量的传递都是以值的方式传递的,如果变量是数组的话,就意味着会将一整个完整的数组进行复制,这样显然不太好。
因此,用指针来传递数组会是个好的选择。
package main
import "fmt"
func valueCopy(arr [5]int){
fmt.Printf("[value]arr: %p \n", &arr)
}
func addrCopy(arr *[5]int){
fmt.Printf("[address]arr: %p \n", arr)
}
func main(){
array := [5]int {4, 5, 6, 7, 8}
fmt.Printf("[base]arr: %p \n", &array)
valueCopy(array)
addrCopy(&array)
}
输出结果:
[root@yikuanzz ~]# go run hello
[base]arr: 0xc00001e060
[value]arr: 0xc00001e090
[address]arr: 0xc00001e060
切片
切片是一种动态数组,可以按照需要增长大小和缩小。
// 底层数组指针、切片长度、切片允许增长到的元素个数
----- ----- -----
| ptr | len | cap |
----- ----- -----
切片的创建和初始化:
1、make 和 切片字面量。
// 创建字符串切片,长度和容量都是 5
slice := make([]string, 5)
// 创建整型切片,长度为 3 ,容量为 5
slice := make([]int, 3, 5)
我们还可以通过切片字面量来声明切片,但是要注意与数组的声明方式做区分。如果我们在 [] 运算符中指定了
// 创建字符串切片
slice := []string {"Red", "Blue", "Green", "Yellow", "Pink"}
// 创建字符串切片
slice := []string {99: ""}
2、nil 和 空切片。
nil 切片是很常见的创建切片的方法,可以用于很多标准库和内置函数。
// 创建 nil 整型切片
var slice []int
// 使用 make 创建空切片
slice := make([]int, 0)
// 使用切片字面量创建空的整型切片
slice := []int {}
切片的使用:
1、赋值和切片
// 创建整型切片并赋值
slice := []int{10, 20, 30, 40, 50}
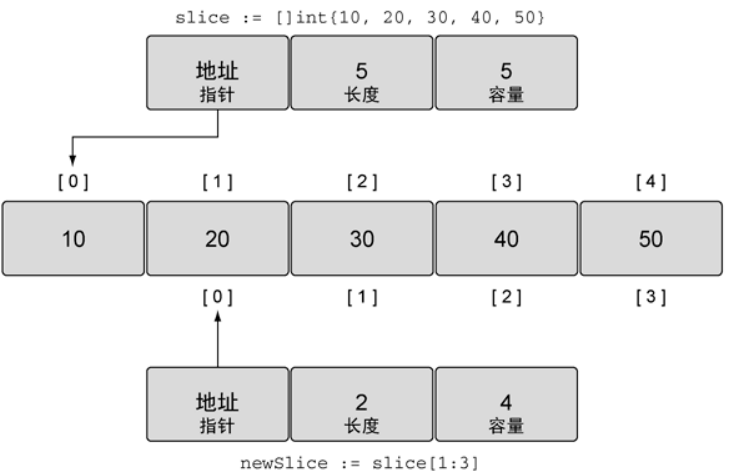
切片之所以叫切片,就是创建一个新的切片就是把底层数组切出一部分。
// 创建一个新切片 前闭后开
newSlice := slice[1:3]
我们仔细观察知道 slice 的切片容量是 5,而 newSlice 的切片容量是 4。为什么呢?
还记得切片的三个元素么,除了长度和容量,还有指针。我们对切片再进行切片时,其实是将指针指向原数组的地址,那么之前作为开头的元素地址我们就不知道了。
2、切片增长
// 创建一个整型切片
slice := []int {10, 20, 30, 40, 50}
// 创建一个新切片
newSlice := slice[1:3]
// 使用原容量分配新元素
newSlice = append(newSlice, 60)
当我们使用 append 函数时,如果底层数组有额外容量,那么就修改对应位置上的数;如果底层数组没有可用容量时,append 函数会创建一个新的底层数组,将被引用的现有的值复制到新数组里,再追加新的值。
函数
append会智能地处理底层数组的容量增长。当切片容量小于 1000 个元素的时候,总是成倍地增加容量。一旦元素超过 1000,容量的增长因子会设为 1.25。当然,具体的增长算法可能会改变。
3、创建切片时的 3 个索引
// 创建字符串切片
source := []string {"Apple", "Orange", "Plum", "Banana", "Grape"}
// 将第三个元素切片,并限制容量
slice := source[2:3:4]
第三个索引的含义是限制新建切片的最大容量。
有一个比较好的用途是,如果切片最大容量为当前切片长度,那么在使用 append 函数时,就能够让其与原有的底层数组分离。
// 创建字符串切片
source := []string {"Apple", "Orange", "Plum", "Banana", "Grape"}
// 将第三个元素切片,并限制容量
slice := source[2:3:3]
// 向 slice 追加新字符串
slice = append(slice, "Kiwi")
此外,append 函数使用 ... 运算符可以将一个切片的所有元素追加到另一个切片里。
// 创建两个切片,并分别用两个整数进行初始化
s1 := []int {1, 2}
s2 := []int {3, 4}
// 将两个切片追加在一起,并显示结果
fmt.Printf("%v \n", append(s1, s2...))
4、迭代切片
Go 语言中也有 range 可以配合 for 来迭代切片里的元素。
// 创建一个整型切片
slice := []int {10, 20, 30, 40}
// 循环迭代
for index, value := range slice{
fmt.Printf("Index: %d Value: %d\n", index, value)
}
当迭代切片时,range 会返回两个值,第一个是当前迭代到的索引位置,第二个值是该位置对应元素的一份副本。
当然,我们也可以用传统的 for 循环搭配 len 函数 和 cap 函数来进行迭代。
多维切片
// 创建一个整型切片的切片
slice := [][]int {{10}, {100, 200}}
因为切片的结构简单,我们通过 append 去增加新的元素也不会有特别大的开销。
// 为第一个切片追加值为 20 的元素
slice[0] = append(slice[0], 20)
函数间传递切片
因为切片的尺寸很小,在函数间复制和传递切片的成本也很低。
// 分配 100 万个整型值的切片
slice := make([]int, le6)
// 将 slice 传递给函数
slice = foo(slice)
// 函数 foo 接收一个整型切片,并返回这个切片
func foo(slice []int) []int{
...
return slice
}
32位 和 64位 系统在 Windows 下基本数据类型的大小都是一样的。只有指针的大小不一样!32位指针大小为 4byte,而 64位 的指针大小为 8byte。
这样我们知道,在 64 位计算机中传递切片,实际上的开销只有 24 个字节。并且,函数中的切片和函数外的切片都是指向同一个底层数组,所以如果在函数修改了切片中数据,那么外面的切片也会察觉到变化。
映射
map 是一种无序的基于 key-value 的数据结构,Go 语言中的 map 是引用类型,必须初始化才能使用。
映射功能强大的地方在于,能够基于键快速检索数据。
映射是一个集合,所以它可以使用处理数组和切片刀方式迭代映射中的元素,但映射是无序的集合,意味着没办法预测键值对被返回的顺序。
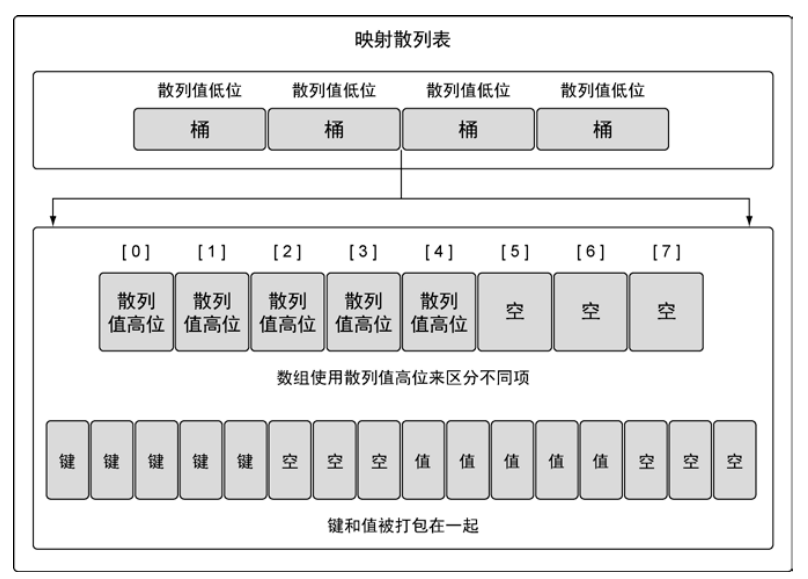
映射最主要的数据结构有两种:哈希查找表(Hash Table)、搜索树(Search Tree)。
哈希表用到哈希函数计算 key 的哈希值,然后根据哈希值将 key 分配到不同的桶里面。随着映射存储的增加,哈希值分布就越均匀,访问键值的速度就越快,映射通过合理数量的桶来平衡键值对的分布。
在 Go 语言中,我们给映射添加键值对时,首先会将根据哈希函数的计算值分别放在“同类”的桶里面,一个桶里面放 8 个 key,就是说桶里面共有 8 个位置,然后同个桶内的 key 会根据哈希值地高 8 位来决定在桶内的具体位置。
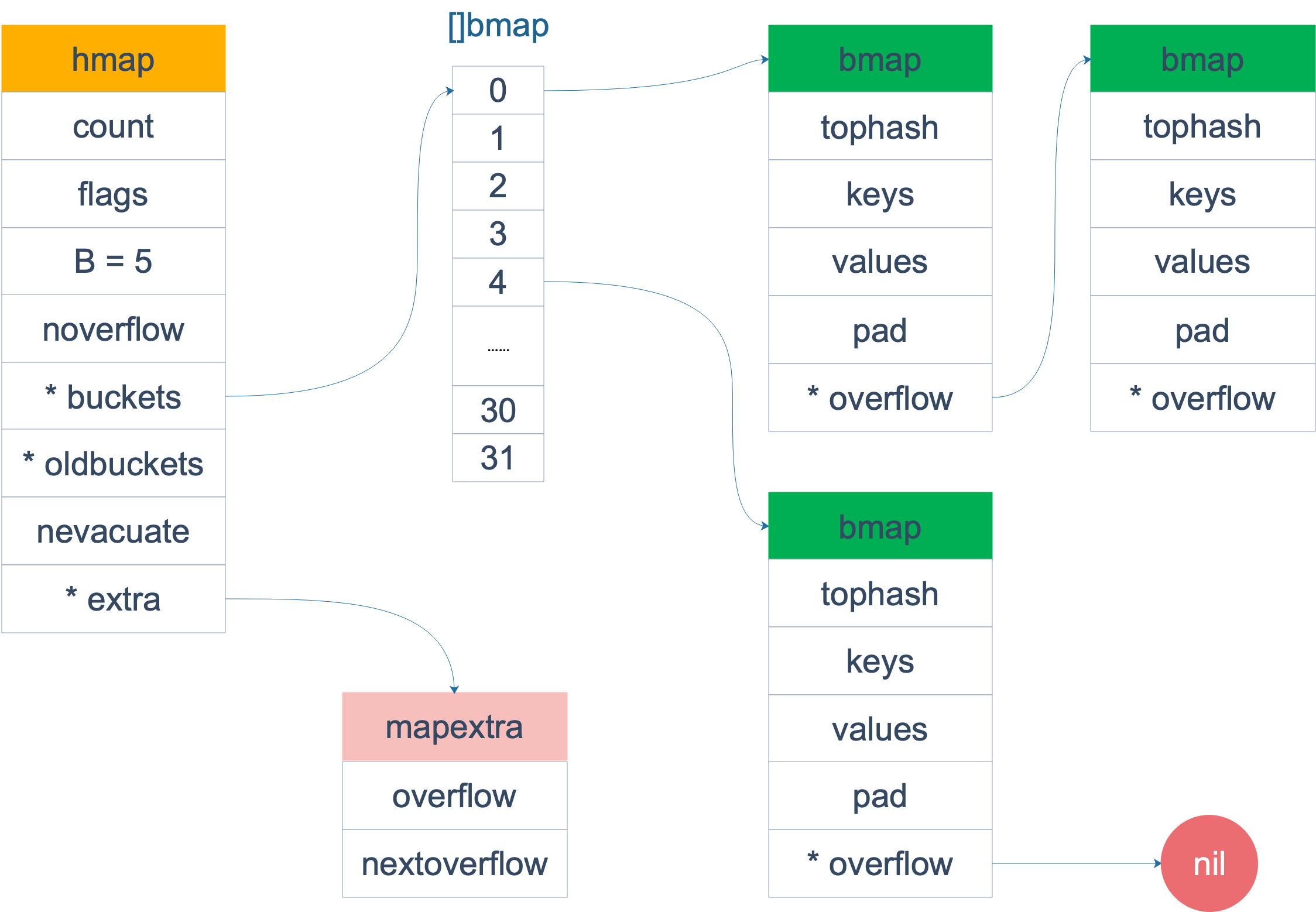
hmap 就是 hashmap 的缩写,bmap 就是“桶”。我们看到 hmap 中的字段,B 是 buckets 数组的长度对数,这里为 5 则 buckets 的长度就是 2 的 5 次方,也就是 32 这么大。
// 桶的数据结构
type bmap struct{
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
每个 bucket 设计成最多只能放 8 个 key-value 对,如果有第 9 个 key-value 落入当前的 bucket,那就需要再构建一个 bucket ,通过 overflow 指针连接起来。
创建和初始化:
// 创建一个映射,键的类型是 string,值的类型是 int
dict := make(map[string]int)
// 创建一个映射,键和值的类型都是 string
// 用两个键值对初始化映射
dict := map[string]string{"Red": "#da1337", "Orange": "#e95a22"}
使用映射:
// 创建空映射,用来存储颜色以及对应的十六进制代码
colors := map[string]string{}
// 将 Red 的代码加入到映射
colors["Red"] = "#da1337"
当然,我们可以通过声明一个未初始化的映射来创建一个值为 nil 的映射,要知道的是 nil 映射不能用用于存储键值对,否则会产生错误。
// 通过声明创建一个 nil 映射
var colors map[string]string
如果我们想从映射中取值的话有两种方式:
- 1、获得值的同时,得到一个标志来确定这个键是否存在。
- 2、只获得值,然后判断这个值是否为零值确定其是否存在。
// 方式1
value, exists := colors["Blue"]
if exists{
fmt.Println(value)
}
// 方式2
value := colors["Blue"]
if value !=""{
fmt.Println(value)
}
同切片一样,映射也能够通过 range 关键字来进行迭代。
// 创建一个映射,存储颜色以及颜色对应的十六进制代码
colors := map[string]string{
"AliceBlue": "#f0f8ff",
"Coral": "#ff7F50",
"DarkGray": "#a9a9a9",
"ForestGreen": "#228b22",
}
// 显示映射里的所有颜色
for key, value := range colors {
fmt.Printf("Key: %s Value: %s\n", key, value)
}
如果我们想把一个键值对从映射里面删除,就要用内置的 delete 函数。
// 删除键为 Coral 的键值对
delete(colors, "Coral")
// 显示映射里面的所有颜色
for key, value := range colors{
fmt.Printf("Key: %s Value: %s \n", key, value)
}
函数间传递映射:
在函数间传递映射并不会重新再建立一个映射副本,它的特性与切片是一样的。就是说,如果在函数中对映射做了修改的话,所有对这个映射的引用都会察觉到这个修改。
func main() {
// 创建一个映射,存储颜色以及颜色对应的十六进制代码
colors := map[string]string{
"AliceBlue": "#f0f8ff",
"Coral": "#ff7F50",
"DarkGray": "#a9a9a9",
"ForestGreen": "#228b22",
}
// 显示映射里的所有颜色
for key, value := range colors {
fmt.Printf("Key: %s Value: %s\n", key, value)
}
// 调用函数来移除指定的键
removeColor(colors, "Coral")
// 显示映射里的所有颜色
for key, value := range colors {
fmt.Printf("Key: %s Value: %s\n", key, value)
}
}
// removeColor 将指定映射里的键删除
func removeColor(colors map[string]string, key string) {
delete(colors, key)
}
Go 语言系统
Go 语言是一种静态类型的编程语言,编译器在编译时得知道程序里每个值的类型。
这样,编译器可以确保程序合理地用值,可以减少潜在的内存异常,并使编译器有机会对代码进行性能优化。
实际上值的类型给编译器提供了两部分信息:
- 1、需要分配多少内存给这个值。
- 2、这段内存表示什么。
用户定义类型
Go 语言允许用户定义类型,其实就是用 struct 关键字来组合字段进行类型的声明。
// 定义一个用户类型
type user struct{
name string
email string
ext int
privileged bool
}
用结构体类型声明变量,初始化时会对其中的字段进行零值初始化。
// 声明 usr 类型的变量,且初始化为零值
var bill user
// 声明 user 类型,并初始化所有字段
lisa := user{
name: "Lisa",
email: "lisa@email.com",
ext: 123,
privileged: true,
}
// 声明 user 类型,并初始化所有字段
john := {"John", "john@eamil.com", 123, true}
方法
方法可以给用户定义的类型添加新的行为。
package main
import "fmt"
// user struct
type user struct{
name string
email string
}
// notify: print information of user
func (u user) notify(){
fmt.Printf("Sending User Email To %s<%s> \n", u.name, u.email)
}
// changeEmail: change email of user
func (u *user) changeEmail(email string){
u.email = email
}
func main(){
bill := user{"Bill", "bill@email.com"}
bill.notify() // value
lisa := &user{"Lisa", "lisa@email.com"}
lisa.notify() // pointer
bill.changeEmail("bill@newdomain.com")
bill.notify()
lisa.changeEmail("lisa@comcast.com")
lisa.notify()
}
关键字 func 和函数名之间的参数被称为接受者,它将函数与接受者的类型绑定。
[root@yikuanzz ~]# go run test
Sending User Email To Bill<bill@email.com>
Sending User Email To Lisa<lisa@email.com>
Sending User Email To Bill<bill@newdomain.com>
Sending User Email To Lisa<lisa@comcast.com>
这里补充一下,Go 语言里面有两种类型的接受者:值接收者 和 指针接收者。
如果用值接收者,那么参数传递的时候会生成一个副本;如果指针接收者,那么参数传递的时候会操作原地址上的数据。
虽然我们在 notify 方法有用指针来去调用,但是它仍是复制了副本,实际上是:(*lisa).notify() 的样子。
类型的本质
1、内置类型。
内置类型就是语言提供的类型:数值类型、字符串类型和布尔类型。
因为是原始的类型,所以我们把这些类型的值传递给方法或函数时,应该传递一个对应值的副本。
// golang.org/src/strings/strings.go:第 620 行到第 625 行
func Trim(s string, cutset string) string{
if s == "" || cutset == ""{
return s
}
return TrimFunc(s, makeCutsetFunc(cutset))
}
2、引用类型。
Go 语言的引用类型有:切片、映射、通道、接口和函数类型。
当这些类型被声明时,创建的变量叫 标头(header) 值。
每个引用类型创建的标头值是包含一个指向底层数据结构的指针,每个引用类型还有一些特殊的字段来管理底层数据结构。
// golang.org/src/net/ip.go:第 32 行
type IP []byte
// golang.org/src/net/ip.go:第 329 行到第 337 行
func (ip IP) MarshalText() ([]byte, error){
if len(ip) == 0{ // 切片直接复制标头值就可以了
return []byte(""), nil
}
if len(ip) != IPv4len && len(ip) != IPv6len{
return nil, errors.New("Invaild IP address")
}
return []byte(ip.String()), nil
}
3、结构类型。
结构类型可以用来描述一组数据值,这组值的本质即可以是原始的,也可以是非原始的。
// golang.org/src/time/time.go:第 39 行到第 55 行
// 原始类型的结构体
type Time struct{
// sec 给出自公元 1 年 1 月 1 日 00:00:00 开始的秒数
sec int64
// nsec 指定了一秒内的纳秒偏移,这个值必须在[0, 999999999]范围内
nsec int32
// loc 用于决定时间对应的当地的分、小时、天和年的值
loc *Location
}
下面的代码,File 类型的实现使用了一个嵌入的指针,指向一个未公开的类型。这层额外的内嵌类型阻止了复制。
// golang.org/src/os/file_unix.go:第 15 行到第 29 行
// 非原始类型的结构体
// File 表示一个打开的文件描述符
type File struct{
*file
}
// file 是 *File 的实际表示
type file struct{
fd int
name string
dirinfo *dirInfo // 除了目录结构,此字段为 nil
nepipe int32 // Write 操作时遇到连续 EPIPE 的次数
}
// golang.org/src/os/file.go:第 238 行到第 240 行
func Open(name string) (file *File, err error){
return OpenFile(name, O_RDONLY, 0)
}
接口
多态是说代码可以根据类型的具体实现采取不同行为的能力。
如果一个类型实现了某个接口,所有使用这个接口的地方,都可以支持这种类型的值。
package main
import (
"fmt"
"io"
"net/http"
"os"
)
// Simple "curl"
func init(){
if len(os.Args) != 2 {
fmt.Println("Usage: ./nnn <url>")
os.Exit(-1)
}
}
func main(){
// Get response from web server
r, err := http.Get(os.Args[1])
if err != nil{
fmt.Println(err)
return
}
// Copy to Stdout from Body
io.Copy(os.Stdout, r.Body)
if err := r.Body.Close(); err != nil{
fmt.Println(err)
}
}
io.Copy 函数中的一个参数必须是实现了 io.Writer 接口的值,第二个参数是必须实现了 io.Reader 接口的值。 当我们将 Body 和 Stdout 这两个值传给 io.Copy 函数后,这个函数会把服务器的数据分成小段,源源不断地传给终端窗口,直到最后一个片段读取并写入终端,io.Copy 函数才返回。
package main
import (
"bytes"
"fmt"
"io"
"os"
)
func main() {
var b bytes.Buffer
// 将字符串写入 Buffer
b.Write([]byte("Hello"))
// 用 Fprintf 将字符串拼接到 Buffer
fmt.Fprintf(&b, "World!")
// 把 Buffer 的内容写到 Stdout
io.Copy(os.Stdout, &b)
}
接口是用来定义行为的类型,这些被定义的行为不由接口直接实现,而是通过方法由用户定义的类型实现。
接口值是一个两字长度的数据结构:
- 1、包含了一个指向内部表的指针,
iTable包含值类型和方法集。 - 2、还有一个指向所存储值的指针。
如果赋值给接口的是指针,那么则会获得其地址上的值 *user。
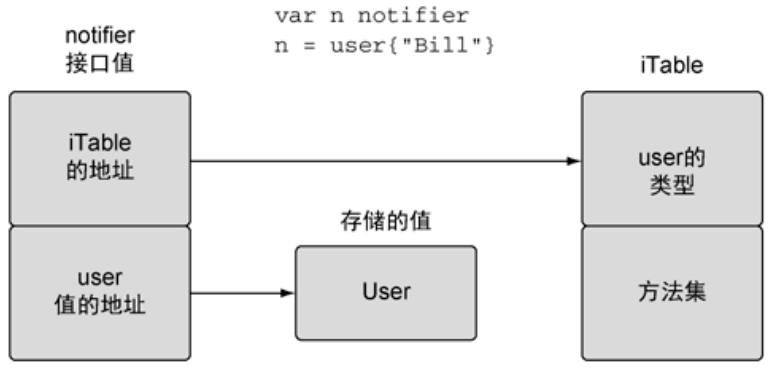
这里稍微解释一下 itab (Interface Table),它是用于实现接口类型和具体类型之间的映射,主要作用是将接口类型和实现该接口的具体类型关联起来,提供一个快速查找机制,以便在运行时进行接口方法的调用。
- 接口类型断言:当进行接口类型断言时,Go 运行时会使用
itab来检查具体类型是否实现了接口。 - 接口方法调用:在调用接口方法时,Go 运行时会通过
itab查找具体类型的方法实现。
type itab struct{
inter *interfacetype // 指向接口类型的定义
_type *_type // 指向实现该接口的具体类型的定义
hash uint32 // 类型的哈希值,用于类型切换
_ [4]byte
fun [1]uintptr // 指向具体类型实现的接口方法函数指针数组 fun[0]=0 表示没有实现
}
假设,我们有一个接口 Speaker 和 一个实现该接口的类型 Dog:
type Speaker interface {
Speak() string
}
type Dog struct{}
func (d Dog) Speak() string{
return "Woof!"
}
在运行的时候,Go 会为 Dog 类型创建一个 itab ,将 Speaker 接口和 Dog 类型关联起来,并存储 Dog 类型实现的 Speak 方法的指针。
方法集定义了接口的接受规则。
我们以方法接受者的视角来看,如果方法接收者是指针,那么给接口的类型就必须是指针类型。
但是,如果方法接收者是值,那么给接口的类型可以是指针类型也可以是值类型。
看到下面这段代码执行就会报错!!
package main
import "fmt"
type People interface{
Speak(string) string
}
type Student struct{}
func (stu *Student) Speak(think string) (talk string) {
if think == "no" {
talk = "I don't like you!"
} else {
talk = "Hello, how are you going?"
}
return
}
func main() {
var peo People = Student{}
think := "bitch"
fmt.Println(peo.Speak(think))
}
[root@yikuanzz ~]# go vet test3
# test3
vet: go/src/test3/pp.go:21:22: cannot use Student{} (value of type Student) as People value in variable declaration: Student does not implement People (method Speak has pointer receiver)
如果要改正的话,就是将 Student{} 改为 &Student{} 就好了。
现在我们明白了这个规则了,但是为什么会这样呢?
事实上,编译器并不是总能自动获得一个值的地址,所以当我们写的方法参数要求传入的是指针的时候,你传入值就会报错。而当写的方案
我们可以看一下这个例子,它用的是
package main
import "fmt"
// duration is based on int
type duration int
// make duration easzier to read
func (d *duration) pretty() string{
return fmt.Sprintf("Duartion: %d", *d)
}
func main(){
// 这样就是不能获取地址的形式
// 如果赋值给变量,然后对变量调用方法就是可行的
duration(42).pretty()
}
接下来,我们再看一看多态行为的例子。
package main
import (
"fmt"
)
// Interface: notifier
type notifier interface{
notify()
}
// Struct: user
type user struct {
name string
email string
}
// pointer method
func (u *user) notify(){
fmt.Printf("Sending user email to %s<%s>\n",
u.name,
u.email)
}
// Struct: admin
type admin struct{
name string
email string
}
// pointer method
func (a *admin) notify(){
fmt.Printf("Sending admin email to %s<%s>\n",
a.name,
a.email)
}
func main(){
bill := user{"Bill", "bill@email.com"}
sendNotification(&bill)
lisa := admin{"Lisa", "lisa@email.com"}
sendNotification(&lisa)
}
func sendNotification(n notifier){ // 多态函数
n.notify()
}
[root@yikuanzz ~]# go run test5
Sending user email to Bill<bill@email.com>
Sending admin email to Lisa<lisa@email.com>
嵌入类型
Go 语言允许用户扩展或修改已有类型的行为,这个功能是通过 嵌入类型(type embedding) 完成的。
嵌入类型是将已有的类型直接声明在新的结构类型里,被嵌入的类型被称为新的外部类型的内部类型。
package main
import "fmt"
type user struct{
name string
email string
}
func (u *user) notify(){
fmt.Printf("Sending user eamil to %s<%s> \n",
u.name,
u.email)
}
type admin struct{
user // embeding type
level string
}
func main(){
// initiate a admin
ad := admin{
user : user{
name: "john smith",
email: "john@yahoo.com",
},
level : "super",
}
ad.user.notify()
ad.notify() // 内部类型的方法被提升到外部类型
}
[root@yikuanzz ~]# go run test6
Sending user eamil to john smith<john@yahoo.com>
Sending user eamil to john smith<john@yahoo.com>
我们对上述例子进行修改添加一个接口:
type notifier interface{
notify()
}
func sendNotification(n notifier){
n.notify()
}
在 main 函数中调用 sendNotification(&ad),这样用于实现接口的内部类型的方法被提升到外部类型。
那么这时候问题来了,如果我们要给 admin 也实现一个方法会怎么样?
func (a *admin) notify(){
fmt.Printf("Sending admin eamil to %s<%s> \n",
a.name,
a.email)
}
我们在 main 函数中执行这些语句:sendNotification(&ad)、ad.user.notify() 和 ad.notify()。
[root@yikuanzz ~]# go run test6
Sending admin eamil to john smith<john@yahoo.com>
Sending user eamil to john smith<john@yahoo.com>
Sending admin eamil to john smith<john@yahoo.com>
我们发现,只有执行 ad.user.notify() 才会调用内部类型的方法。
所以,我们可以得出的结论是:
- 当我们只实现了内部类方法的时候,不论何种方式调用的就是内部类方法。
- 如果我们两个方法都实现了的时候,那么只有调用内部类再调用其实现的方法才会真的调用。
公开或未公开的标识符
如果想设计好的 API,是需要用某种规则来控制声明后的标识符的可见性。
Go 语言支持从包里公开或隐藏标识符,通过这个功能,让用户能按照自己的规划控制标识符的可见性。
其实,如果我们知道私有变量和公有变量的概念就很好理解了,因为就是一个道理。
标识符的名字小写字母开头的,那么这个标识符就是未公开的;如果标识符的名字大写字母开头的,那么这个标识符就是公开的。
我们一般用工厂函数来对未公开的标识符进行操作,其实就是用函数来创建对象,为它添加数性和方法,然后返回这个对象。
// entities
package entities
type user struct{
Name string
Email string
}
type Admin struct{
user // 嵌入类型未公开
Rights int
}
// main
package main
import (
"fmt"
"entities"
)
func main(){
a := entities.Admin{
Right: 10,
}
// 可设置内部类型公开字段的值
a.Name = "Bill"
a.Email = "bill@email.com"
fmt.Printf("User: %v \n", a)
}
因为 user 不是公开的,所以不能直接通过字面量构建;但是内部类型公开的标识符是可以通过外部类型来访问,并进行初始化的。
Go 并发
并发与并行
在开始 Go 语言并发编程之前,我们先简单地了解一些概念:
-
1、进程和线程:
- 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。
- 线程是进程的一个执行实例,是 CPU 调度和分派的基本单位。
- 一个进程可以创建和撤销多个线程;同一个进程中的多个线程之间可以并发执行。
-
2、协程和线程:
- 协程,独立的栈空间,共享堆空间,调度由用户自己控制。
- 线程,在一个线程上可以跑多个协程,就是说协程是轻量级的线程。
-
3、并发和并行:
-
多线程程序在一个核心的 CPU 上运行,就是并发,并发主要由切换时间片来实现"同时"运行。

-
多线程程序在多个核心的 CPU 上运行,就是并行,并行是直接利用多核实现多线程的运行。
-
Go 语言中的并发其实就是能让某个函数独立于其他函数运行的能力。当一个函数创建为 goroutine 时,Go 会将其视为一个独立的工作单元,这个单元会被调度到可用的逻辑处理器上执行。
Go 语言通过运行时的调度器来管理被创建的所有 goroutine 并为其分配执行时间。这个调度器在操作系统之上,将操作系统的线程与语言运行时的逻辑处理器绑定,并在逻辑处理器上运行 goroutine。
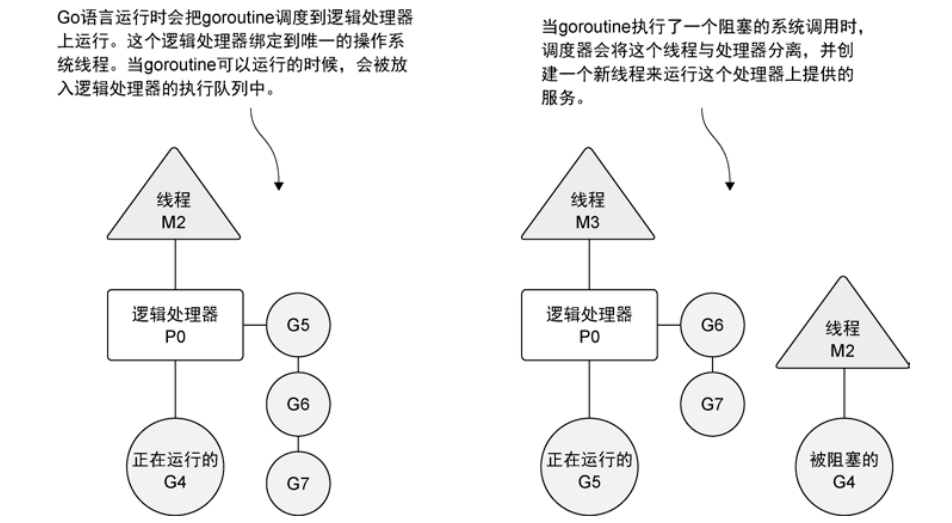
有时,正在运行的 goroutine 需要执行阻塞的系统调用,比如打开一个文件,这时线程和 goroutine 会从逻辑处理器上分离,并且这个线程会继续阻塞直到系统调用返回。
此时,逻辑处理器就失去了线程,于是调度器会新建一个线程,并将其绑定到逻辑处理器上,然后在从本地运行队列里选择另一个 goroutine 来运行。
一旦被阻塞的系统调用执行完成并返回,对应的 goroutine 会回到本地运行队列,而之前的线程会被维护,以便之后可以继续使用。
如果一个 goroutine 要做一个网络 I/O 调用的话,goroutine 就不用逻辑处理器,而是移到集成了网络轮询器的运行时。一旦该轮询器指示某个网络读或写操作已就绪,对应的 goroutine 就会重新分配到逻辑处理器上来完成操作。(调度器对可以创建的逻辑处理器的数量没有限制,默认每个程序最多创建 10 000 个线程。)
所以,当 goroutine 并行的时候,就会有多个逻辑处理器,这时调度器会将 goroutine 平等分配到每个逻辑处理器上,这样 goroutine 就会在不同的线程上同时运行。
goroutine
我们看一看 goroutine 的例子,它创建两个协程,以并发的形式分别显示大写和小写的英文字母。
package main
import (
"fmt"
"runtime"
"sync"
)
func main(){
// 分配一个逻辑处理器给调度器
runtime.GOMAXPROCS(1)
// wg 等待程序完成
var wg sync.WaitGroup
// 等待 2 个 goroutine 完成
wg.Add(2)
fmt.Println("Start Goroutines")
// 匿名函数 小写
go func(){
defer wg.Done() // 完成计数减1
for count := 0; count < 3; count++{
for char := 'a' char < 'a'+26; char++{
fmt.Printf("%c ", char)
}
}
}()
// 匿名函数 大写
go func(){
defer wg.Done() // 完成计数减1
for count := 0; count < 3; count++{
for char := 'A' char < 'A'+26; char++{
fmt.Printf("%c ", char)
}
}
}()
fmt.Println("Waiting To Finish")
wg.Wait()
fmt.Println("Terminating Program")
}
此外,我们知道的是,一个正在运行的 goroutine 在工作结束前,是可以被停止并重新调度的。因为,如果一个 goroutine 在一定时间内没有完成它的任务就会被挂起,然后切换到另一个 goroutine 去执行它的任务。
我们也可以通过给每个核心分配一个逻辑处理器去处理任务。
import "runtime"
// 给每个可用的核心分配一个逻辑处理器
runtime.GOMAXPROCS(runtime.NumCPU())
竞争状态
如果两个或者多个 goroutine 在没有互相同步的情况下,访问某个共享的资源,并试图同时读和写这个资源,就处于相互竞争的状态,这种情况被称作 竞争状态(race candition)。
对于一个共享资源的读写操作必须是原子化的,也就是说同一时刻下,只能有一个 goroutine 对共享资源进行读和写操作。
package main
import (
"fmt"
"runtime"
"sync"
)
var (
counter int
wg sync.WaitGroup
)
func main(){
wg.Add(2)
go incCounter(1)
go incCounter(2)
wg.Wait()
fmt.Println("Final Counter:", counter)
}
func incCounter(id int){
defer wg.Done()
for count := 0; count < 2; count++{
value := counter // 获取 counter 值
runtime.Gosched() // 把 goroutine 退出并放回队列
value++ // 增加本地 value 值
counter = value // 将值保存到 counter
}
}
我们可以用 go build -race 来检测程序中的竞争,当然,为了消除竞争状态,我们可以通过 Go 提供的锁机制来锁住共享资源,来保证 goroutine 的同步状态。
锁住共享资源
如果需要顺序访问一个整型变量或一段代码,atomic 和 sync 包的函数提供了很好的解决方案。
原子函数能以很底层的加锁机制来同步访问整型变量和指针。
package main
import (
"fmt"
"runtime"
"sync"
"sync/atomic"
)
var (
counter int64
wg sync.WaitGroup
)
func main(){
wg.Add(2)
go incCounter(1)
go incCounter(2)
wg.Wait()
fmt.Println("Final Counter:" , counter)
}
func incCounter(id int) {
defer wg.Done()
for count:=0; count < 2; count++{
// 安全地对 counter 加 1
atomic.AddInt64(&counter, 1)
runtime.GOsched()
}
}
我们使用的 AddInt64 函数会同步整型的加法,强制同时只有一个 goroutine 运行并完成这个加法操作,另外的原子函数是 LoadInt64 和 StoreInt64 ,这两个函数提供了一种安全地读和写一个整型值的方式。
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
var (
shuntdown int64
wg sync.WaitGroup
)
func main(){
wg.Add(2)
go doWork("A")
go doWork("B")
time.Sleep(1 * time.Second)
fmt.Println("Shutdown Now")
atomic.StoreInt64(&shutdown, 1)
wg.Wait()
}
func doWork(name string){
defer wg.Done()
for {
fmt.Printf("Doing %s Work \n", name)
time.Sleep(250 * time.Millisecond)
if atmoic.LoadInt64(&shutdown) == 1{
fmt.Printf("Shutting %s Down \n", name)
break
}
}
}
另一种同步访问共享资源的方式是使用 互斥锁(mutex)。互斥锁用于在代码上创建一个临界区,保证同一时间只有一个 goroutine 可以执行这个临界区代码。
package main
import (
"fmt"
"runtime"
"sync"
)
var (
counter int
wg sync.WaitGroup
mutex sync.Mutex
)
func main(){
wg.Add(2)
go incCounter(1)
go incCounter(2)
wg.Wait()
fmt.Printf("Final Counter: %d\\n", counter)
}
func incCounter(id int){
defer wg.done()
for count := 0; count < 2; count++{
mutex.Lock(){
value := counter
runtime.Gosched()
value++
counter = value
}
mutex.Unlock()
}
}
通道
在 Go 中,除了使用原子函数和互斥锁来保证对共享资源的安全访问以及消除竞争状态,还可以使用通道,通过发送和接收需要共享的资源,在 goroutine 之间做同步。
声明通道时,需要指定将要被共享的数据的类型。
// 创建一个无缓冲的整型通道
unbuffered := make(chan int)
// 创建一个有缓冲的通道
buffered := make(chan string 10)
// 通过通道发送一个字符串
buffered <- "Gopher"
// 从通道接收一个字符串
value := <- buffered
无缓冲通道(unbuffered channel) 是指在接收前没有能力保存任何值的通道,它要求发送和接收的 goroutine 必须是准备好的,因此它们这中交互的行为就是同步的,如果没准备好,那么另一方就会阻塞等待。
我们用两个 goroutine 来模拟网球比赛,并用无缓冲的通道来模拟球的来回。
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var wg sync.WaitGroup
func init(){
rand.Seed(time.Now().UnixNano())
}
func main(){
court := make(chan int)
wg.Add(2)
go player("Nadal", court)
go player("Djokovic", court)
}